
基础数据
1 | baidu CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 0 - - - 11451601 - "JSP3/2.0.14" "-" "-" "-" http - 2 v1.go2yd.com 0.002 25136186 16384 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1531818470104-11451601-112.29.213.66#2705261172 644514568 |
项目新建
- idea新建项目
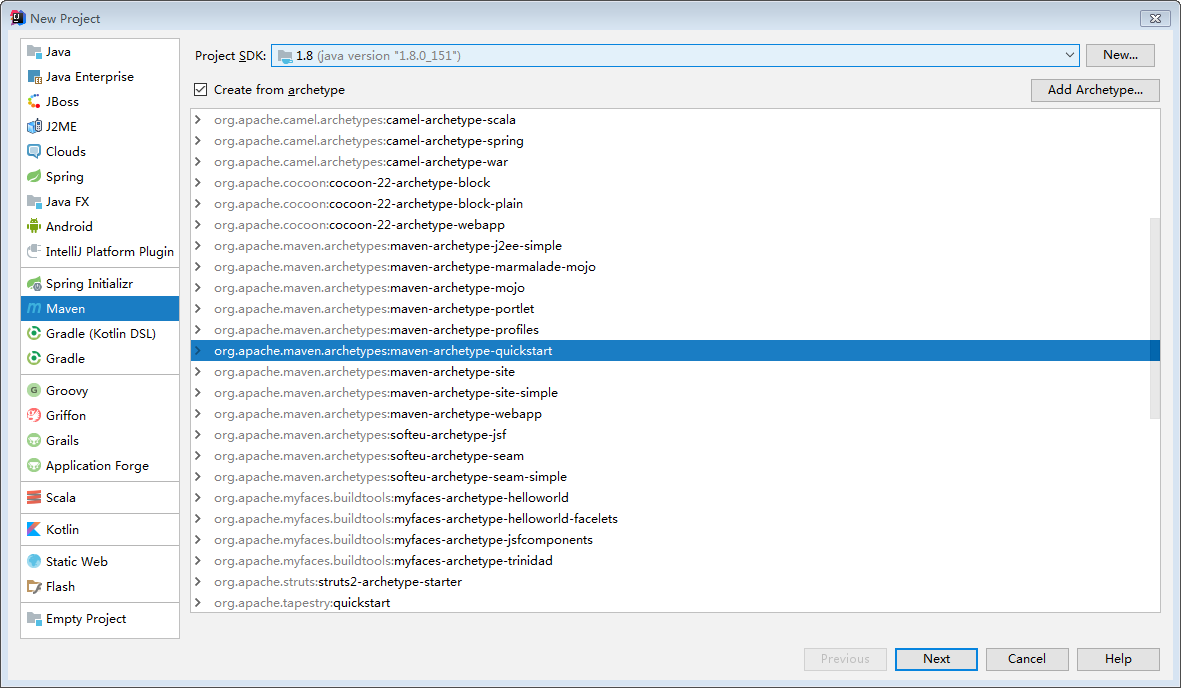
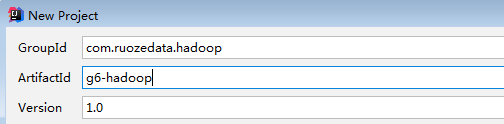
- 选择自己安装的maven


- 删除app文件
pom.xml文件修改
1 |
|
代码开发
LogUtils功能类开发
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47package com.ruozedata.hadoop.utils;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
public class LogUtils {
DateFormat sourceFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
DateFormat targetFormat = new SimpleDateFormat("yyyyMMddHHmmss");
/**
* 日志文件解析,对内容进行字段的处理
* 按/t分隔
*/
public String parse(String log){
String result = "";
String[] split = log.split("\t");
String cdn = split[0];
String region = split[1];
String level = split[3];
String timeStr = split[4];
String time = timeStr.substring(1,timeStr.length()-7);
try {
time = targetFormat.format(sourceFormat.parse(time));
String ip = split[6];
String domain = split[10];
String url = split[12];
String trafic = split[20];
StringBuilder builder = new StringBuilder();
builder.append(cdn).append("\t")
.append(region).append("\t")
.append(level).append("\t")
.append(time).append("\t")
.append(ip).append("\t")
.append(domain).append("\t")
.append(url).append("\t")
.append(trafic).append("\t");
result = builder.toString();
} catch (ParseException e) {
e.printStackTrace();
}
return result;
}
}解释
1
2
3
4
5
6
7在功能类里我们做了这么几步操作
- 通过parse接收一个log参数
- 对log参数按照'\t'进行分割
- 按照数组的下标依次取出我们需要的字段
- 对时间字段进行了处理
- 将[17/Jul/2018:17:07:50 +0800]格式的时间转化为20180717170750
- 将字段进行重新按照'\t'分隔,进行组装return
LogETLMapper类开发
1 | package com.ruozedata.hadoop.mapreduce.mapper; |
- 解释
1
2
3
4
5
6
7- 在LogETLMapper中首先我们继承了Mapper类
- 由于ETL是不需要reduce操作的,这里我们可以看到Mapper定义的reduce参数的key是NullWritable
- 重写map方法
- 判断value的lenth是否是我们预期的72个字符
- 如果不是,我们丢掉这条数据
- 如果是,调用我们开发好的LogUtils.parse方法对数据进行处理
- 调用context.write方法将数据写入上下文
LogETLDriver类开发
1 | package com.ruozedata.hadoop.mapreduce.driver; |
- 解释
1
2
3
4
5
6- 首先通过args读入两个参数作为输入路径和输出路径
- 判断输出路径是否存在
- 如果存在删除输出路径
- 设置map类(MapperClass、MapOutputKeyClass、MapOutputValueClass)
- 设置mapreduce的输入和输出路径
- 设置结束后将程序设置为成功
代码打包并进行执行测试
- 使用maven的package功能进行打包
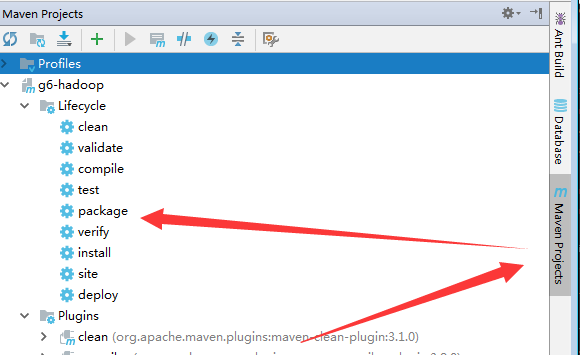
完毕后通过日志可以看到我们的jar包已经打出来了
1
2
3
4
5
6
7
8
9
10
11[INFO] --- maven-jar-plugin:3.0.2:jar (default-jar) @ g6-hadoop ---
[INFO] Building jar: D:\高铁6号\g6-train-hadoop\target\g6-hadoop-1.0.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 16.362 s
[INFO] Finished at: 2019-03-29T19:40:56+08:00
[INFO] Final Memory: 30M/278M
[INFO] ------------------------------------------------------------------------
- jar目录在D:\高铁6号\g6-train-hadoop\target\g6-hadoop-1.0.jar将jar包上传到服务器上
1
2yum install lrzsz
rz 我们的jar包将我们的原始日志文件上传到hdfs中
1
2
3
4baidu.log
baidu CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 11451601 - "JSP3/2.0.14" "-" "-" "-" http - 2 v1.go2yd.com 0.002 25136186 16384 - - - - - - - - 1531818470104-11451601-112.29.213.66#2705261172 644514568
baidu CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 11451601 - "JSP3/2.0.14" "-" "-" "-" http - 2 v1.go2yd.com 0.002 25136186 16384 - - - - - - - - 1531818470104-11451601-112.29.213.66#2705261172 644514568
baidu CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 11451601 - "JSP3/2.0.14" "-" "-" "-" http - 2 v1.go2yd.com 0.002 25136186 16384 - - - - - - - - 1531818470104-11451601-112.29.213.66#2705261172 644514568
1 | hadoop fs -mkdir /g6/logs |
- 执行jar包的方法
1
hadoop jar g6-hadoop-1.0.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /g6/logs /g6/baidulog/day=20180717
1 | 我们在参数中指定了输出路径为/g6/baidulog/day=20180717 |
结合hive
新建一个外部表g6_access
1
2
3
4
5
6
7
8
9
10
11
12create external table g6_access (
cdn string,
region string,
level string,
time string,
ip string,
domain string,
url string,
traffic bigint
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/g6/baidulog/' ;通过alert命令刷新数据
1
2
3
4
5
6
7
8
9alter table g6_access add if not exists partition(day='20180717');
select * from g6_access;
g6_access.cdn g6_access.region g6_access.level g6_access.time g6_access.ip g6_access.domain g6_access.url g6_acc
baidu CN E 20180717170750 223.104.18.110 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c
baidu CN E 20180717170750 223.104.18.110 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c
baidu CN E 20180717170750 223.104.18.110 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c
- 可以看到数据已经都进来了